This volume describes in detail the structure of the Evolution of Terrestrial Ecosystems (ETE) computerized database. Its publication is meant to serve three purposes. First, it will function as a practical manual for those researchers actively compiling data for entry into the ETE Database. A more limited version of this volume has been in use within the ETE Consortium since 1988. This 1997 edition replaces the 1993 version. Second, the present edition contains sufficient information to make a computerized database having a structure and data fields that are compatible with the current ETE Database. We hope that it is useful as a guide to some of the practical aspects of the design of paleontological databases, whether or not the goals of such databases are the same as those of the ETE Database. Finally, we wish to inform our colleagues about the progress we have made in representing much of the extraordinarily complex body of information that makes up the terrestrial fossil record in a form that is compatible with a computerized relational database management system. Of course, not all of the details of the fossil record can be adequately represented in such a database. Also, we anticipate a continuing expansion and revision of the current scheme. However, we feel that the ETE Consortium has made a substantial start on the integration of paleoecologically relevant data from paleozoology, paleobotany and sedimentology. Bringing together such disparate pieces of information, from such diverse sources, is the major goal of this project. We expect that data compiled under the current design will prove useful, regardless of how the scheme may be modified or augmented in the future. Further revisions will draw on our experience, and that of our colleagues, based on the way that the ETE Database functions as a research tool.
Many proposed and existing electronic databases in natural science involve the computerization of large databases that already exist in other media, such as catalogues, specimen labels, or bibliographies. These databases are intended primarily as reference and data-management tools for collections of objects or documents that researchers must consult in the course of a project. The ETE Database is different in that it is designed primarily to support research directly. That is, it will contain the raw material for many investigations and comparative analyses. Researchers will not use it only to find data stored elsewhere; rather, the relevant data for many questions will already be present, and the necessary research activity involved in getting the data to this point will have already been performed. Such a research database is not really new to paleontology. In a real sense a traditional museum collection represents the same kind of open-ended, long-term data resource (Damuth, 1991). There, the investment in field work and curation results in an ever-expanding and constantly updated collection of information that can be the basis of biostratigraphic, phylogenetic and comparative studies. What is novel is the attempt to use data stored electronically as such a shared resource, accumulating over time the work of many researchers. The ETE Database is of course ultimately based largely on the content of museum collections, but because of its focus on general issues in paleoecology it contains only some of the information that can be abstracted from a given collection of fossils. For example, individual specimens are not represented in the ETE Database. However, at the same time, the ETE Database integrates information from many different museums and the results of varied research in sedimentology, taphonomy, paleoecology, and functional morphology. Thus one could consider that implementing this database constitutes the building of an electronic "meta-museum" for paleoecology, and for paleontology in general. This does not by any means make the basic fossil collections obsolete, but it gives researchers access to large amounts of previously scattered information, with unprecedented powers of manipulation for comparison and analysis. Such a project has only recently become practical in a research environment, with the advent of relatively inexpensive, powerful computer workstations, highly sophisticated database management software, graphical user interfaces, and the Internet. The success of projects such as this one may have a significant impact upon the way that paleontology is done -- and taught -- in the future.
The move from traditional information resources to a computerized database system requires a subtle change in ways of thinking about data. In a computerized system, consistency of representation is critical and must be enforced even if some nuances and detail are thereby not recorded. To search effectively on some attribute, the terms describing that attribute must be standardized. Free-form "comment" fields can be searched, but usually at a high cost in efficiency. However, it is not possible, or even desirable, to include all information in searchable fields. Some readers may feel that the categories and lists of valid values we use may cause some data to be abstracted beyond the level of usefulness, or that we have omitted important kinds of information or detail from the Database altogether. But, not all of this information is relevant to the currently stated goals of the ETE Database. And, some of this rich, ancillary detail can be included in comment fields that users may read to obtain a fuller understanding of the standardized data. From a database designer's point of view, we have probably been too liberal in our use of comment fields and in the storage of overlapping information under different headings. However, purity of design is in this case not as important as is minimizing the chance of losing important information. This is why we often allow several routes to a given conclusion, and why we must remain flexible enough to modify the database structure to accommodate information of newly recognized importance.
Some readers may be dismayed that we have provided no mechanisms for enforcing standardized taxonomic nomenclature or for dealing with synonymy at any taxonomic level. However, a successful computerized system for correcting and standardizing taxonomic entries is far more difficult to design than it might first appear. Without including the nomenclature history of individual specimens (a level below that at which the ETE Database operates), it is virtually impossible to guarantee that synonymies would be processed and implemented correctly. Furthermore, the maintenance of some kind of up-to-date synonymy engine for all terrestrial species would be a prohibitively time consuming task. Regretfully, we concluded that it was not feasible for us to develop computerized standardization of taxonomic nomenclature. Nevertheless, we use the names of species and higher taxa in our species lists. Traditional classifications, though not necessarily representing phylogenetic relationships unambiguously or without distortion, nevertheless provide a general organizational scheme that is familiar to most biologists and that gives at least some clues to genealogical relationships and adaptive similarity. Coherent and consistent species nomenclature is essential for tracing lineages and assessing historical relationships among communities and regions, all of which may be of value in inferring the actions of ecological and evolutionary processes. Of course, for many of the kinds of comparative studies that the Database is designed to facilitate, the "species" in a locality's species list will be primarily the bearers of ecological attributes. As long as the ecological attributes of the species at a locality are accurate, it may not matter what the species is called or how it is classified. In any case, we are committed to maintaining a level of taxonomic accuracy and consistency that will be adequate to fulfill the research potential of the Database, and that will exhibit a reasonable correspondence to standard practice in those fields more directly involved with formal systematic research.
This volume is not a computer user's manual in the conventional sense. It does not provide instructions for the operation of any software, although it briefly describes the computer applications that the ETE Consortium uses to interact with the database. Rather, the structure of the database as described here can be implemented in a variety of computer environments and on systems of various degrees of complexity. However, although good database design is important in facilitating database maintenance, it is ultimately the user interface and details of the local implementation that are responsible for enforcing and maintaining consistency of the data.
The ETE Consortium
The ETE Consortium was established in 1988 by a group of paleontologists associated with the Evolution of Terrestrial Ecosystems Program, which they had initiated the year before at the National Museum of Natural History, Smithsonian Institution. These researchers (A.K. Behrensmeyer, J. Damuth, W.A. DiMichele, R. Potts, H.-D. Sues and S. Wing) recognized that they shared common interests and perspectives in the study of terrestrial paleoecology. In particular, they felt that a coordinated effort to investigate long-term patterns in the history of terrestrial biotas and paleocommunities was overdue. Such an approach is needed to augment the traditional foci of paleobiology -- species-level adaptations and phylogenetic relationships -- in order to address questions about coevolution, the relationship of environmental factors to evolutionary change, the nature of ecological associations and the factors that influence their stability or transformation, and the effects of major global environmental changes on the Earth's biota.
Our knowledge of fossil assemblages and paleoenvironments should allow us to investigate the ecological or evolutionary processes that cause community and ecosystem change over geological time. The documentation of repeated historical patterns of community or ecosystem change should form the empirical base upon which theories about such processes are erected and evaluated. To uncover general or recurrent patterns in community or ecosystem history we must go beyond a mere listing of sequential biotas and formations. We need to develop a comparative paleoecology. That is, we must attempt to identify observable structural or functional characteristics of paleocommunities and paleoecosystems that are independent of geologic age and taxonomic composition. This will allow meaningful comparisons of the biological properties of communities and ecosystems as entities in themselves -- either to assess stability and change in these characters or to relate these characters to external physical environmental variables. To a large extent this is unexplored territory; the relevant characteristics to measure and compare over such spans of time are not well understood, and much remains to be discovered through continued empirical research. Nevertheless, some promising approaches are suggested by ecological theory and observations of extant ecosystems and communities. As an initial step, the ETE researchers chose to concentrate on the large class of descriptive community characteristics that use as basic building blocks the functional morphological characteristics and inferred ecological roles of the community's species. Such characteristics as body-size distributions, predator-prey ratios, and percentages of entire-margined leaves are community characters of this type. In addition, direct inferences about ecosystem characteristics and paleoenvironments are often possible and can play a critical role in paleoecological interpretations.
This comparative study of ecosystems and species associations across spans of geologic time, combined with the study and reconstruction of paleoenvironments and the ecological characteristics of individual fossil species, incorporates both an ecological and an evolutionary perspective and constitutes the field of evolutionary paleoecology. For a fuller discussion of terrestrial evolutionary paleoecology and a review of the current state of the field, see the volume resulting from the first Evolution of Terrestrial Ecosystems Conference, sponsored by the ETE Program (Behrensmeyer et al. 1992).
Research in evolutionary paleoecology requires the integration of large amounts of information that is ordinarily either scattered throughout a vast paleontological and geological literature or lies in unpublished form in museum collections. Furthermore, the ecological characteristics inferred from functional research on fossil plants and animals are themselves elementary data that can be generated and evaluated independently of any analysis or comparison of community structure. The information base for paleoecology spans numerous disciplines, including geology, anthropology, and ecology and paleobiology of both plants and animals.
No one researcher can adequately cover all of this intellectual territory in his or her primary research activities, yet paleoecologists frequently must have access to relevant data and interpretations that come from outside their area of direct expertise. Early in the planning discussions of the ETE Program it became evident that a centralized database and some interdisciplinary standardization would facilitate communication among researchers working on related questions, and would be needed to undertake the kinds of broad comparative studies we envisioned. The potential size and complexity of such a database called for computerized database management. A computerized research database would integrate and accumulate, in a form accessible to all, the research results and literature compilations undertaken by numerous workers. Once committed to establishing such a database, we realized that if we planned carefully enough the ETE Database could continue to grow as a general resource, potentially including data on all significant terrestrial fossil localities.
In 1988, the ETE Consortium was established to oversee all aspects of the ETE Database. The Consortium is intended to coordinate the largely independent data-compilation projects for the ETE Database, which may involve researchers from different institutions and with varying degrees of association with the Consortium's activities as a whole. In addition, the Consortium, through regular meetings, decides upon changes to the Database structure, the data fields, and their formats. It also establishes goals for the performance and functionality of the customized software applications that users employ to interact with the database. The software applications are developed at Santa Barbara. The Consortium is independent of any particular institutional program or source of funding, and its membership is subject to change over time. Currently, Consortium members are located in the Departments of Paleobiology and Anthropology, National Museum of Natural History, the Department of Ecology, Evolution and Marine Biology, University of California at Santa Barbara, and the Department of Geology, University of Helsinki, Finland. Identical copies of the current database are maintained at the Consortium's three locations.
The ETE Database
The ETE Database is designed to allow broad-scale comparisons of the paleobiology and paleoecology of terrestrial ecosystems and their plant and animal communities. By allowing researchers rapid access to a large array of standardized information it will facilitate detailed comparisons on a locality-by-locality basis of paleocommunity structure, paleovegetation, and paleoenvironments, and the tracing of patterns of biological structural change in terrestrial ecosystems over geologic time. The Database allows direct analyses to be performed on its contents, and allows interactive access for browsing the contents and formulating specific queries.
The basic entity in the ETE Database is a fossil locality -- a significant collection of fossil specimens from a particular geographic location. For each locality, besides its name, age, and location, there are a number of fields of sedimentological, taphonomic, and paleoecological data (including inferences about paleovegetation and paleoenvironment). In addition, for each locality there is a species list, and for each species in the Database a set of 25-30 morphological and ecological descriptors. These fields are all described in detail in this volume.
The ETE Database software runs on Hewlett-Packard UNIX workstations at all locations. The database management software used is a commercially available, full-featured, SQL relational database management system (CA-Ingres, Computer Associates, Alameda, California). Relational databases and the structure of the ETE Database are discussed more fully in the next subsection. The entry and modification of data are accomplished through a custom forms-based utility program (the Data Manager). This data-entry program performs sophisticated error-detection and transparently executes a number of required data transformations. It also automatically documents changes made to existing data fields. The database may be queried using SQL (the industry-standard database query language), or it may be accessed through a graphical interface program (the Explorer) that displays fossil localities on maps. The system allows researchers to see the localities that satisfy arbitrarily complicated (Boolean) conditions specified by the user. Data sets for statistical analysis can be generated from the graphics interface using a menu-based utility. The Data Manager, the Explorer, and the database software are designed to operate within the context of a local network of Windows PCs or Macintoshes connected to the UNIX workstations. In addition, in 1998 the Consortium expects to provide World Wide Web access to a version of the ETE Database, and to release software that remote users can use to access the database contents via the Internet from their own computers. The ETE Consortium web page is at http://etewb.lscf.ucsb.edu.
Relational Databases
In relational databases, data appear to the user as if they are contained in one or more tables, which may be thought of as containing columns (the attributes of each entry or record) and rows (the individual records). Conceptually, the tables are the only structures in the database -- no "links" or other structures connecting the tables are evident. Tables are named, for reference, but do not necessarily correspond to particular files on disk or other physical objects containing stored information. The user asks for data, ultimately, by executing a command that says something like, "Get me such-and-such from table so-and-so". The user tells the software what data are required, but does not give the computer specific instructions specifying how to retrieve them. The user's (and, by extension, the user-interface if that is what is generating the actual query) database queries need not know the details of how and where the data are physically located or stored -- the database management software takes care of this, as well as trying to figure out the best way to search the database for the requested information. (This is a principle called data independence.)
Data may be stored in many different database tables within the database. Although there are no hard-coded links among the tables, the data in one table may be (and must be in a properly designed database) logically related to the data in another table. The key to designing a relational database is to organize the data into tables such that the logical relationships allow one to store and retrieve all needed data, while minimizing the chance that updates will cause important data to become inconsistent or will result in deletions or changes that were not intended.
For example, imagine a simple database where each record consists of a paleontologist's name, the university affiliation of the paleontologist, and the city in which the university is located. These data could all be placed in three columns in a single table (Fig. 1). Initially, each university is always associated with its proper city. However, suppose for one paleontologist we change the university entry, but neglect to change the city entry for the same record. Now, in answer to questions about which paleontologist works in which city, or about the location of a particular university, the database may give the wrong answer. For example, a given university may be listed as being in two cities at once.
| Paleontologist 1 | Harvard | Cambridge |
| Paleontologist 2 | Yale | New Haven |
| Paleontologist 3 | UCLA | Los Angeles |
| Paleontologist 4 | Yale | New Haven |
The solution is to separate the information into two tables, each representing a logically distinct association of real-world information (Fig. 2). Data Table 1 represents paleontologists and their universities, and Data Table 2 represents universities and their locations. The two tables are related to each other by matching entries in the university column. Now, changing a university in Data Table 1 cannot change the relationship between universities and cities, and the paleontologist's city is automatically updated. A query sent to the database management software often has to be slightly more complicated in a case such as that in Fig. 2, since to get a city for a paleontologist one must specify that one wants the city in Data Table 2 whose university entry matches the university entry in Data Table 1 for the targeted paleontologist. In practice, the computer takes care of the details. Note that this works only if each entry in the university column in Data Table 2 is unique -- otherwise, it is possible for a university to be listed twice or more, each time as being in a different city, and there is no logical way to know which is correct. In database terminology, the university column in Data Table 2 must be a primary key. A table's primary key is a unique identifier for each record. It may be composed of the entries of more than one column (a composite key) if, taken together, they are necessary to create a unique record. A column in one table whose entries match those of the primary key of another table is called a foreign key. An example is the university column in Data Table 1. It is through the primary keys that the tables of a relational database are connected. A full and very readable explanation of the basics of relational databases can be found in Date (1995).
|
|
Figure 2. Hypothetical database arranged in two tables.
Structure of the ETE Database
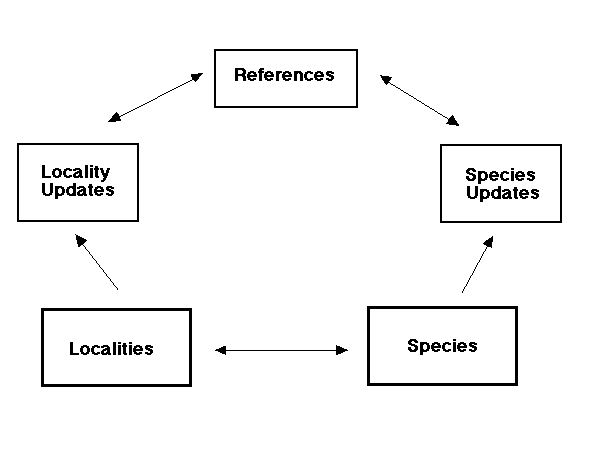
Now we are ready to consider the structure of the ETE Database specifically. The two basic real-world entities that must be recorded in the database are localities and species. Since species are found at localities, there is an obvious set of logical relations between these two entities. However, we also need to associate other information with these entries. Each time a locality or species is entered into the database, or each time information about one or the other is changed, we should want to know what was done, when, who did it, and why. This information should be stored separately from the localities or species, since some might be updated many more times than others, and there is no way to predict how much space would be needed. Also, we would like to retain the full update history of a locality or species. In addition, we want to have more information about the source of the data, whether it is a literature reference, unpublished notes, or original research. For simplicity, we will call all such information a "reference." Figure 3 shows an outline of the major relationships among tables in the ETE Database.
Figure 3. Simplified outline of the structure of the ETE Database. Single-headed arrows indicate one-to-many relationships (e.g., one locality can have many updates, but each update entry belongs to only one locality). Double-headed arrows indicate many-to-many relationships (e.g., each locality can have many species, and each species can be found at many localities). Only the major data tables are shown.
A complete listing of the data fields, and the tables in which they are arranged, is given in Table 1. Following the table, the detailed structure (or schema) of the ETE Database is presented graphically in Fig. 4. The information in Table 1 should be sufficient to build the ETE Database structure within any relational database management system. For each table, the fields are listed, along with their data formats and brief descriptions. The order of fields in the tables is irrelevant in a relational database. A truly relational database management system also should not require the user to specify which columns constitute primary or foreign keys. These designations in Table 1 are only to assist the reader in understanding the logical connections among the data tables. In most cases the primary key is a field identified as an "ID number." These values are unique integers supplied by the data-entry software at the time a locality or species is first entered. Different database software products may offer different ways to assign unique, sequential values to records.
Data formats for the various fields are listed in their most general form: integer, float (floating-point, real number), date (a format frequently used in data bases to allow arithmetic operations on dates and times), and character fields (indicated by "c" followed by a number expressing the length of the field, in characters). Not all of these formats may be available in a given database product. In addition, other choices may be available, such as a distinction between fixed-length and variable-length text, different levels of floating-point precision, or different "sizes" of integers. The ETE Database uses 4-bit integers, which allow over 2 X 109 values, rather than the limit of 32,768 that is frequently found in microcomputer applications.